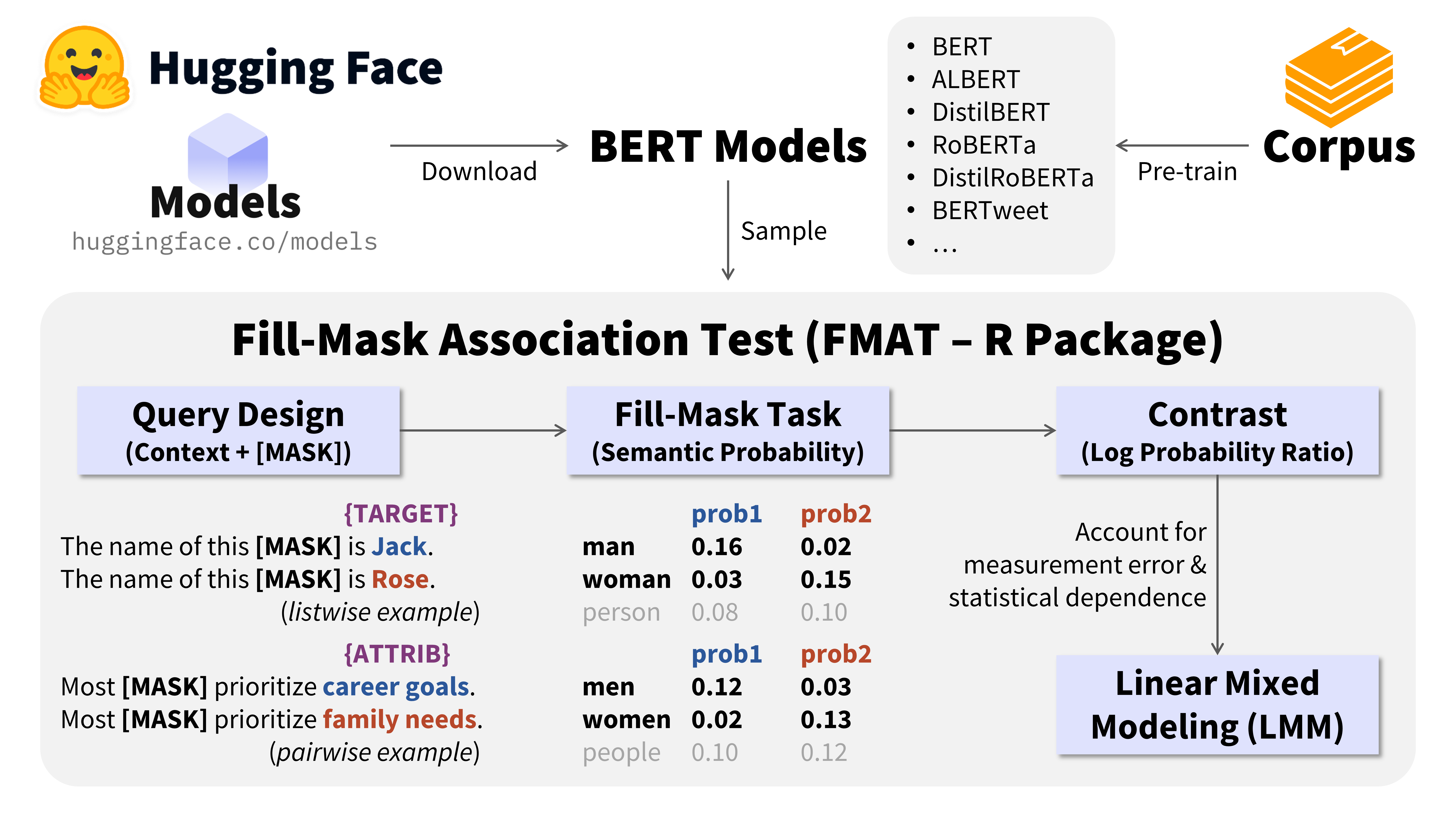
😷 The Fill-Mask Association Test (掩码填空联系测验).
The Fill-Mask Association Test (FMAT) is an integrative, probability-based social computing method using BERT Models to measure conceptual associations (e.g., attitudes, biases, stereotypes, social norms, cultural values) as propositional semantic representations in natural language (Bao, 2024, JPSP).
⚠️ Please update this package to version ≥ 2026.1 for better functionality.

Citation
(1) FMAT Package
- Bao, H. W. S. (2023). FMAT: The Fill-Mask Association Test. https://doi.org/10.32614/CRAN.package.FMAT
(2) FMAT Research Articles - Methodology
- Bao, H. W. S. (2024). The Fill-Mask Association Test (FMAT): Measuring propositions in natural language. Journal of Personality and Social Psychology, 127(3), 537–561. https://doi.org/10.1037/pspa0000396
(3) FMAT Research Articles - Applications
- Bao, H. W. S., & Gries, P. (2024). Intersectional race–gender stereotypes in natural language. British Journal of Social Psychology, 63(4), 1771–1786. https://doi.org/10.1111/bjso.12748
- Bao, H. W. S., & Gries, P. (2025). Biases about Chinese people in English language use: Stereotypes, prejudice and discrimination. China Quarterly, 263, 830–842. https://doi.org/10.1017/S0305741025100532
- Wang, Z., Xia, H., Bao, H. W. S., Jing, Y., & Gu, R. (2025). Artificial intelligence is stereotypically linked more with socially dominant groups in natural language. Advanced Science, 12(39), e08623. https://doi.org/10.1002/advs.202508623
Installation
Besides the R package FMAT, you also need to have a Python environment and install three Python packages (transformers, huggingface-hub, and torch).
(1) R Package
## Method 1: Install from CRAN
install.packages("FMAT")
## Method 2: Install from GitHub
install.packages("devtools")
devtools::install_github("psychbruce/FMAT", force=TRUE)(2) Python Environment and Packages
Install Anaconda (an environment/package manager that automatically installs Python, its IDEs like Spyder, and a large list of common Python packages).
Set RStudio to “Run as Administrator” to enable pip command in Terminal.
RStudio (find “rstudio.exe” in its installation path)
→ File Properties → Compatibility → Settings
→ Tick “Run this program as an administrator”
Open RStudio and specify the Anaconda’s Python interpreter.
RStudio → Tools → Global/Project Options
→ Python → Select → Conda Environments
→ Choose “…/Anaconda3/python.exe”
Check Python packages installed and versions:
(with Terminal in RStudio or Command Prompt on Windows system)
pip listInstall Python packages “transformers”, “huggingface-hub”, and “torch”.
You may install either the latest versions (with better support for modern models) or specific versions (with downloading progress bars).
Option 1: Install Latest Versions (with Better Support for Modern Models)
For CPU users:
pip install transformers huggingface-hub torchFor GPU (CUDA) users:
pip install transformers huggingface-hub
pip install torch --index-url https://download.pytorch.org/whl/cu130- See Guidance for GPU Acceleration if you have an NVIDIA GPU device on your PC and would use GPU to accelerate the pipeline. See also PyTorch Build Command and install CUDA Toolkit 13.0.
Option 2: Install Specific Versions (with Downloading Progress Bars)
For CPU users:
pip install transformers==4.40.2 huggingface-hub==0.20.3 torch==2.2.1For GPU (CUDA) users:
pip install transformers==4.40.2 huggingface-hub==0.20.3
pip install torch==2.2.1 --index-url https://download.pytorch.org/whl/cu121- According to the May 2024 releases, “transformers” ≥ 4.41 depends on “huggingface-hub” ≥ 0.23. The “transformers” (4.40.2) and “huggingface-hub” (0.20.3) can display progress bars when downloading BERT models.
- Proxy users may use the “global mode” (全局模式) to download models.
- If you find the error
HTTPSConnectionPool(host='huggingface.co', port=443), please try to (1) reinstall Anaconda so that some unknown issues may be fixed, or (2) downgrade the “urllib3” package to version ≤ 1.25.11 (pip install urllib3==1.25.11) so that it will use HTTP proxies (rather than HTTPS proxies as in later versions) to connect to Hugging Face.
Guidance for FMAT
Step 1: Download BERT Models
Use set_cache_folder() to change the default HuggingFace cache directory from “%USERPROFILE%/.cache/huggingface/hub” to another folder you like, so that all models would be downloaded and saved in that folder. Keep in mind: This function takes effect only for the current R session temporarily, so you should run this each time BEFORE you use other FMAT functions in an R session.
Use BERT_download() to download BERT models. A full list of BERT models are available at Hugging Face.
Use BERT_info() and BERT_vocab() to obtain detailed information of BERT models.
Step 2: Design FMAT Queries
Design queries that conceptually represent the constructs you would measure (see Bao, 2024, JPSP for how to design queries).
Use FMAT_query() and/or FMAT_query_bind() to prepare a data.table of queries.
Step 3: Run FMAT
Use FMAT_run() to get raw data (probability estimates) for further analysis.
Several steps of preprocessing have been included in the function for easier use (see FMAT_run() for details).
- For BERT variants using
<mask>rather than[MASK]as the mask token, the input query will be automatically modified so that users can always use[MASK]in query design. - For some BERT variants, special prefix characters such as
\u0120and\u2581will be automatically added to match the whole words (rather than subwords) for[MASK].
Notes
- Improvements are ongoing, especially for more diverse (less popular) BERT models.
- If you have problems using the functions, please report at GitHub Issues.
Guidance for GPU Acceleration
By default, the FMAT package uses CPU to enable the functionality for all users. But for advanced users who want to accelerate the pipeline with GPU, the FMAT_run() function supports using a GPU device.
Test results (on the developer’s computer, depending on BERT model size):
- CPU (Intel 13th-Gen i7-1355U): 500~1000 queries/min
- GPU (NVIDIA GeForce RTX 2050): 1500~3000 queries/min
Checklist:
- Ensure that you have an NVIDIA GPU device (e.g., GeForce RTX Series) and an NVIDIA GPU driver installed on your system.
- Install PyTorch (Python
torchpackage) with CUDA support.- Find guidance for installation command at https://pytorch.org/get-started/locally/.
- CUDA is available only on Windows and Linux, but not on MacOS.
- If you have installed a version of
torchwithout CUDA support, please first uninstall it (command:pip uninstall torch). - You may also install the corresponding version of CUDA Toolkit (e.g., for the
torchversion supporting CUDA 12.1, the same version of CUDA Toolkit 12.1 may also be installed).
BERT Models
Classic 12 English Models
The reliability and validity of the following 12 English BERT models for the FMAT have been established in our earlier research.
(model name on Hugging Face - model file size)
- bert-base-uncased (420 MB)
- bert-base-cased (416 MB)
- bert-large-uncased (1283 MB)
- bert-large-cased (1277 MB)
- distilbert-base-uncased (256 MB)
- distilbert-base-cased (251 MB)
- albert-base-v1 (45 MB)
- albert-base-v2 (45 MB)
- roberta-base (476 MB)
- distilroberta-base (316 MB)
- vinai/bertweet-base (517 MB)
- vinai/bertweet-large (1356 MB)
For details about BERT, see:
- What is Fill-Mask? [HuggingFace]
- An Explorable BERT [HuggingFace]
- BERT Model Documentation [HuggingFace]
- Illustrated BERT
- Visual Guide to BERT
library(FMAT)
models = c(
"bert-base-uncased",
"bert-base-cased",
"bert-large-uncased",
"bert-large-cased",
"distilbert-base-uncased",
"distilbert-base-cased",
"albert-base-v1",
"albert-base-v2",
"roberta-base",
"distilroberta-base",
"vinai/bertweet-base",
"vinai/bertweet-large"
)
BERT_download(models)ℹ Device Info:
R Packages:
FMAT 2024.5
reticulate 1.36.1
Python Packages:
transformers 4.40.2
torch 2.2.1+cu121
NVIDIA GPU CUDA Support:
CUDA Enabled: TRUE
CUDA Version: 12.1
GPU (Device): NVIDIA GeForce RTX 2050
── Downloading model "bert-base-uncased" ──────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 570/570 [00:00<00:00, 114kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 48.0/48.0 [00:00<00:00, 23.9kB/s]
vocab.txt: 100%|██████████| 232k/232k [00:00<00:00, 1.50MB/s]
tokenizer.json: 100%|██████████| 466k/466k [00:00<00:00, 1.98MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 440M/440M [00:36<00:00, 12.1MB/s]
✔ Successfully downloaded model "bert-base-uncased"
── Downloading model "bert-base-cased" ────────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 570/570 [00:00<00:00, 63.3kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 49.0/49.0 [00:00<00:00, 8.66kB/s]
vocab.txt: 100%|██████████| 213k/213k [00:00<00:00, 1.39MB/s]
tokenizer.json: 100%|██████████| 436k/436k [00:00<00:00, 10.1MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 436M/436M [00:37<00:00, 11.6MB/s]
✔ Successfully downloaded model "bert-base-cased"
── Downloading model "bert-large-uncased" ─────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 571/571 [00:00<00:00, 268kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 48.0/48.0 [00:00<00:00, 12.0kB/s]
vocab.txt: 100%|██████████| 232k/232k [00:00<00:00, 1.50MB/s]
tokenizer.json: 100%|██████████| 466k/466k [00:00<00:00, 1.99MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 1.34G/1.34G [01:36<00:00, 14.0MB/s]
✔ Successfully downloaded model "bert-large-uncased"
── Downloading model "bert-large-cased" ───────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 762/762 [00:00<00:00, 125kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 49.0/49.0 [00:00<00:00, 12.3kB/s]
vocab.txt: 100%|██████████| 213k/213k [00:00<00:00, 1.41MB/s]
tokenizer.json: 100%|██████████| 436k/436k [00:00<00:00, 5.39MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 1.34G/1.34G [01:35<00:00, 14.0MB/s]
✔ Successfully downloaded model "bert-large-cased"
── Downloading model "distilbert-base-uncased" ────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 483/483 [00:00<00:00, 161kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 48.0/48.0 [00:00<00:00, 9.46kB/s]
vocab.txt: 100%|██████████| 232k/232k [00:00<00:00, 16.5MB/s]
tokenizer.json: 100%|██████████| 466k/466k [00:00<00:00, 14.8MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 268M/268M [00:19<00:00, 13.5MB/s]
✔ Successfully downloaded model "distilbert-base-uncased"
── Downloading model "distilbert-base-cased" ──────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 465/465 [00:00<00:00, 233kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 49.0/49.0 [00:00<00:00, 9.80kB/s]
vocab.txt: 100%|██████████| 213k/213k [00:00<00:00, 1.39MB/s]
tokenizer.json: 100%|██████████| 436k/436k [00:00<00:00, 8.70MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 263M/263M [00:24<00:00, 10.9MB/s]
✔ Successfully downloaded model "distilbert-base-cased"
── Downloading model "albert-base-v1" ─────────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 684/684 [00:00<00:00, 137kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 25.0/25.0 [00:00<00:00, 3.57kB/s]
spiece.model: 100%|██████████| 760k/760k [00:00<00:00, 4.93MB/s]
tokenizer.json: 100%|██████████| 1.31M/1.31M [00:00<00:00, 13.4MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 47.4M/47.4M [00:03<00:00, 13.4MB/s]
✔ Successfully downloaded model "albert-base-v1"
── Downloading model "albert-base-v2" ─────────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 684/684 [00:00<00:00, 137kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 25.0/25.0 [00:00<00:00, 4.17kB/s]
spiece.model: 100%|██████████| 760k/760k [00:00<00:00, 5.10MB/s]
tokenizer.json: 100%|██████████| 1.31M/1.31M [00:00<00:00, 6.93MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 47.4M/47.4M [00:03<00:00, 13.8MB/s]
✔ Successfully downloaded model "albert-base-v2"
── Downloading model "roberta-base" ───────────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 481/481 [00:00<00:00, 80.3kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 25.0/25.0 [00:00<00:00, 6.25kB/s]
vocab.json: 100%|██████████| 899k/899k [00:00<00:00, 2.72MB/s]
merges.txt: 100%|██████████| 456k/456k [00:00<00:00, 8.22MB/s]
tokenizer.json: 100%|██████████| 1.36M/1.36M [00:00<00:00, 8.56MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 499M/499M [00:38<00:00, 12.9MB/s]
✔ Successfully downloaded model "roberta-base"
── Downloading model "distilroberta-base" ─────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 480/480 [00:00<00:00, 96.4kB/s]
→ (2) Downloading tokenizer...
tokenizer_config.json: 100%|██████████| 25.0/25.0 [00:00<00:00, 12.0kB/s]
vocab.json: 100%|██████████| 899k/899k [00:00<00:00, 6.59MB/s]
merges.txt: 100%|██████████| 456k/456k [00:00<00:00, 9.46MB/s]
tokenizer.json: 100%|██████████| 1.36M/1.36M [00:00<00:00, 11.5MB/s]
→ (3) Downloading model...
model.safetensors: 100%|██████████| 331M/331M [00:25<00:00, 13.0MB/s]
✔ Successfully downloaded model "distilroberta-base"
── Downloading model "vinai/bertweet-base" ────────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 558/558 [00:00<00:00, 187kB/s]
→ (2) Downloading tokenizer...
vocab.txt: 100%|██████████| 843k/843k [00:00<00:00, 7.44MB/s]
bpe.codes: 100%|██████████| 1.08M/1.08M [00:00<00:00, 7.01MB/s]
tokenizer.json: 100%|██████████| 2.91M/2.91M [00:00<00:00, 9.10MB/s]
→ (3) Downloading model...
pytorch_model.bin: 100%|██████████| 543M/543M [00:48<00:00, 11.1MB/s]
✔ Successfully downloaded model "vinai/bertweet-base"
── Downloading model "vinai/bertweet-large" ───────────────────────────────────────
→ (1) Downloading configuration...
config.json: 100%|██████████| 614/614 [00:00<00:00, 120kB/s]
→ (2) Downloading tokenizer...
vocab.json: 100%|██████████| 899k/899k [00:00<00:00, 5.90MB/s]
merges.txt: 100%|██████████| 456k/456k [00:00<00:00, 7.30MB/s]
tokenizer.json: 100%|██████████| 1.36M/1.36M [00:00<00:00, 8.31MB/s]
→ (3) Downloading model...
pytorch_model.bin: 100%|██████████| 1.42G/1.42G [02:29<00:00, 9.53MB/s]
✔ Successfully downloaded model "vinai/bertweet-large"
── Downloaded models: ──
size
albert-base-v1 45 MB
albert-base-v2 45 MB
bert-base-cased 416 MB
bert-base-uncased 420 MB
bert-large-cased 1277 MB
bert-large-uncased 1283 MB
distilbert-base-cased 251 MB
distilbert-base-uncased 256 MB
distilroberta-base 316 MB
roberta-base 476 MB
vinai/bertweet-base 517 MB
vinai/bertweet-large 1356 MB
✔ Downloaded models saved at C:/Users/Bruce/.cache/huggingface/hub (6.52 GB)
BERT_info(models) model size vocab dims mask
<fctr> <char> <int> <int> <char>
1: bert-base-uncased 420MB 30522 768 [MASK]
2: bert-base-cased 416MB 28996 768 [MASK]
3: bert-large-uncased 1283MB 30522 1024 [MASK]
4: bert-large-cased 1277MB 28996 1024 [MASK]
5: distilbert-base-uncased 256MB 30522 768 [MASK]
6: distilbert-base-cased 251MB 28996 768 [MASK]
7: albert-base-v1 45MB 30000 128 [MASK]
8: albert-base-v2 45MB 30000 128 [MASK]
9: roberta-base 476MB 50265 768 <mask>
10: distilroberta-base 316MB 50265 768 <mask>
11: vinai/bertweet-base 517MB 64001 768 <mask>
12: vinai/bertweet-large 1356MB 50265 1024 <mask>(Tested 2024-05-16 on the developer’s computer: HP Probook 450 G10 Notebook PC)
General 32 English and 32 Chinese Models
We are using a more comprehensive list of 32 English BERT models and 32 Chinese BERT models in our ongoing and future projects.
library(FMAT)
set_cache_folder("G:/HuggingFace_Cache/") # models saved in portable SSD
## 32 English Models
models.en = c(
# BERT (base/large/large-wwm, uncased/cased)
"bert-base-uncased",
"bert-base-cased",
"bert-large-uncased",
"bert-large-cased",
"bert-large-uncased-whole-word-masking",
"bert-large-cased-whole-word-masking",
# ALBERT (base/large/xlarge, v1/v2)
"albert-base-v1",
"albert-base-v2",
"albert-large-v1",
"albert-large-v2",
"albert-xlarge-v1",
"albert-xlarge-v2",
# DistilBERT (uncased/cased/distilroberta)
"distilbert-base-uncased",
"distilbert-base-cased",
"distilroberta-base",
# RoBERTa (roberta/muppet-roberta, base/large)
"roberta-base",
"roberta-large",
"facebook/muppet-roberta-base",
"facebook/muppet-roberta-large",
# BART (base/large)
"facebook/bart-base",
"facebook/bart-large",
# ELECTRA (base/large)
"google/electra-base-generator",
"google/electra-large-generator",
# MobileBERT (uncased)
"google/mobilebert-uncased",
# ModernBERT (base/large)
"answerdotai/ModernBERT-base", # transformers >= 4.48.0
"answerdotai/ModernBERT-large", # transformers >= 4.48.0
# [Tweets] (BERT/RoBERTa/BERTweet-base/BERTweet-large)
"muhtasham/base-mlm-tweet",
"cardiffnlp/twitter-roberta-base",
"vinai/bertweet-base",
"vinai/bertweet-large",
# [PubMed Abstracts] (BiomedBERT, base/large)
"microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract",
"microsoft/BiomedNLP-BiomedBERT-large-uncased-abstract"
)
## 32 Chinese Models
models.zh = c(
# BERT [Google]
"bert-base-chinese",
# BERT [Alibaba-PAI] (base/ck-base/ck-large/ck-huge)
"alibaba-pai/pai-bert-base-zh",
"alibaba-pai/pai-ckbert-base-zh",
"alibaba-pai/pai-ckbert-large-zh",
"alibaba-pai/pai-ckbert-huge-zh",
# BERT [HFL] (wwm, bert-wiki/bert-ext/roberta-ext)
"hfl/chinese-bert-wwm",
"hfl/chinese-bert-wwm-ext",
"hfl/chinese-roberta-wwm-ext",
# BERT [HFL] (lert/macbert/electra, base/large)
"hfl/chinese-lert-base",
"hfl/chinese-lert-large",
"hfl/chinese-macbert-base",
"hfl/chinese-macbert-large",
"hfl/chinese-electra-180g-base-generator",
"hfl/chinese-electra-180g-large-generator",
# ALBERT [UER] (base/large)
"uer/albert-base-chinese-cluecorpussmall",
"uer/albert-large-chinese-cluecorpussmall",
# RoBERTa [UER] (H=512/768, L=6/8/10/12)
"uer/chinese_roberta_L-6_H-512",
"uer/chinese_roberta_L-8_H-512",
"uer/chinese_roberta_L-10_H-512",
"uer/chinese_roberta_L-12_H-512",
"uer/chinese_roberta_L-6_H-768",
"uer/chinese_roberta_L-8_H-768",
"uer/chinese_roberta_L-10_H-768",
"uer/chinese_roberta_L-12_H-768",
# RoBERTa [UER] (wwm, base/large)
"uer/roberta-base-wwm-chinese-cluecorpussmall",
"uer/roberta-large-wwm-chinese-cluecorpussmall",
# BERT [IDEA-CCNL] (MacBERT/TCBert-base/TCBert-large)
"IDEA-CCNL/Erlangshen-MacBERT-325M-NLI-Chinese",
"IDEA-CCNL/Erlangshen-TCBert-330M-Classification-Chinese",
"IDEA-CCNL/Erlangshen-TCBert-330M-Sentence-Embedding-Chinese",
# RoBERTa [IDEA-CCNL] (UniMC, base/large)
"IDEA-CCNL/Erlangshen-UniMC-RoBERTa-110M-Chinese",
"IDEA-CCNL/Erlangshen-UniMC-RoBERTa-330M-Chinese",
# MegatronBERT [IDEA-CCNL] (huge)
"IDEA-CCNL/Erlangshen-UniMC-MegatronBERT-1.3B-Chinese"
)
BERT_info(models.en)
BERT_info(models.zh)Information of the English Models
model type param vocab embed layer heads mask
<fctr> <fctr> <int> <int> <int> <int> <int> <fctr>
1: bert-base-uncased bert 109482240 30522 768 12 12 [MASK]
2: bert-base-cased bert 108310272 28996 768 12 12 [MASK]
3: bert-large-uncased bert 335141888 30522 1024 24 16 [MASK]
4: bert-large-cased bert 333579264 28996 1024 24 16 [MASK]
5: bert-large-uncased-whole-word-masking bert 335141888 30522 1024 24 16 [MASK]
6: bert-large-cased-whole-word-masking bert 333579264 28996 1024 24 16 [MASK]
7: albert-base-v1 albert 11683584 30000 128 12 12 [MASK]
8: albert-base-v2 albert 11683584 30000 128 12 12 [MASK]
9: albert-large-v1 albert 17683968 30000 128 24 16 [MASK]
10: albert-large-v2 albert 17683968 30000 128 24 16 [MASK]
11: albert-xlarge-v1 albert 58724864 30000 128 24 16 [MASK]
12: albert-xlarge-v2 albert 58724864 30000 128 24 16 [MASK]
13: distilbert-base-uncased distilbert 66362880 30522 768 6 12 [MASK]
14: distilbert-base-cased distilbert 65190912 28996 768 6 12 [MASK]
15: distilroberta-base roberta 82118400 50265 768 6 12 <mask>
16: roberta-base roberta 124645632 50265 768 12 12 <mask>
17: roberta-large roberta 355359744 50265 1024 24 16 <mask>
18: facebook/muppet-roberta-base roberta 124645632 50265 768 12 12 <mask>
19: facebook/muppet-roberta-large roberta 355359744 50265 1024 24 16 <mask>
20: facebook/bart-base bart 139420416 50265 768 6 12 <mask>
21: facebook/bart-large bart 406291456 50265 1024 12 16 <mask>
22: google/electra-base-generator electra 33511168 30522 768 12 4 [MASK]
23: google/electra-large-generator electra 50999552 30522 1024 24 4 [MASK]
24: google/mobilebert-uncased mobilebert 24581888 30522 128 24 4 [MASK]
25: answerdotai/ModernBERT-base modernbert 149014272 50368 768 22 12 [MASK]
26: answerdotai/ModernBERT-large modernbert 394781696 50368 1024 28 16 [MASK]
27: muhtasham/base-mlm-tweet bert 109482240 30522 768 12 12 [MASK]
28: cardiffnlp/twitter-roberta-base roberta 124645632 50265 768 12 12 <mask>
29: vinai/bertweet-base roberta 134899968 64001 768 12 12 <mask>
30: vinai/bertweet-large roberta 355359744 50265 1024 24 16 <mask>
31: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract bert 109482240 30522 768 12 12 [MASK]
32: microsoft/BiomedNLP-BiomedBERT-large-uncased-abstract bert 335141888 30522 1024 24 16 [MASK]
model type param vocab embed layer heads maskMissing values of year tokens (1800~2019):
-
"albert"series: 3 missing- 1807, 1809, 1817
-
"ModernBERT"series: 65 missing- 1801~1829, 1831~1839, 1841~1847, 1849, 1851~1859, 1869, 1871~1875, 1877~1879, 1883
-
"roberta"series,"muppet"series,"bart"series,"distilroberta-base","cardiffnlp/twitter-roberta-base","vinai/bertweet-large": 79 missing- 1801~1829, 1831~1839, 1841~1849, 1851~1859, 1864, 1866~1869, 1871~1879, 1881~1885, 1887, 1891, 1892, 1894
-
"vinai/bertweet-base": 29 missing- 1801~1811, 1813~1814, 1816~1819, 1821~1823, 1825~1829, 1831, 1833, 1834, 1843
-
"BiomedBERT"series: 163 missing- 1801~1949, 1951~1959, 1961~1964, 1967
Information of the Chinese Models
model type param vocab embed layer heads mask
<fctr> <fctr> <int> <int> <int> <int> <int> <fctr>
1: bert-base-chinese bert 102267648 21128 768 12 12 [MASK]
2: alibaba-pai/pai-bert-base-zh bert 102267648 21128 768 12 12 [MASK]
3: alibaba-pai/pai-ckbert-base-zh bert 102269184 21130 768 12 12 [MASK]
4: alibaba-pai/pai-ckbert-large-zh bert 325524480 21130 1024 24 16 [MASK]
5: alibaba-pai/pai-ckbert-huge-zh megatron-bert 1257367552 21248 2048 24 8 [MASK]
6: hfl/chinese-bert-wwm bert 102267648 21128 768 12 12 [MASK]
7: hfl/chinese-bert-wwm-ext bert 102267648 21128 768 12 12 [MASK]
8: hfl/chinese-roberta-wwm-ext bert 102267648 21128 768 12 12 [MASK]
9: hfl/chinese-lert-base bert 102267648 21128 768 12 12 [MASK]
10: hfl/chinese-lert-large bert 325522432 21128 1024 24 16 [MASK]
11: hfl/chinese-macbert-base bert 102267648 21128 768 12 12 [MASK]
12: hfl/chinese-macbert-large bert 325522432 21128 1024 24 16 [MASK]
13: hfl/chinese-electra-180g-base-generator electra 22108608 21128 768 12 3 [MASK]
14: hfl/chinese-electra-180g-large-generator electra 41380096 21128 1024 24 4 [MASK]
15: uer/albert-base-chinese-cluecorpussmall albert 10547968 21128 128 12 12 [MASK]
16: uer/albert-large-chinese-cluecorpussmall albert 16548352 21128 128 24 16 [MASK]
17: uer/chinese_roberta_L-6_H-512 bert 30258688 21128 512 6 8 [MASK]
18: uer/chinese_roberta_L-8_H-512 bert 36563456 21128 512 8 8 [MASK]
19: uer/chinese_roberta_L-10_H-512 bert 42868224 21128 512 10 8 [MASK]
20: uer/chinese_roberta_L-12_H-512 bert 49172992 21128 512 12 8 [MASK]
21: uer/chinese_roberta_L-6_H-768 bert 59740416 21128 768 6 12 [MASK]
22: uer/chinese_roberta_L-8_H-768 bert 73916160 21128 768 8 12 [MASK]
23: uer/chinese_roberta_L-10_H-768 bert 88091904 21128 768 10 12 [MASK]
24: uer/chinese_roberta_L-12_H-768 bert 102267648 21128 768 12 12 [MASK]
25: uer/roberta-base-wwm-chinese-cluecorpussmall bert 102267648 21128 768 12 12 [MASK]
26: uer/roberta-large-wwm-chinese-cluecorpussmall bert 325522432 21128 1024 24 16 [MASK]
27: IDEA-CCNL/Erlangshen-MacBERT-325M-NLI-Chinese bert 325625856 21229 1024 24 16 [MASK]
28: IDEA-CCNL/Erlangshen-TCBert-330M-Classification-Chinese bert 325522432 21128 1024 24 16 [MASK]
29: IDEA-CCNL/Erlangshen-TCBert-330M-Sentence-Embedding-Chinese bert 325522432 21128 1024 24 16 [MASK]
30: IDEA-CCNL/Erlangshen-UniMC-RoBERTa-110M-Chinese bert 102267648 21128 768 12 12 [MASK]
31: IDEA-CCNL/Erlangshen-UniMC-RoBERTa-330M-Chinese bert 325522432 21128 1024 24 16 [MASK]
32: IDEA-CCNL/Erlangshen-UniMC-MegatronBERT-1.3B-Chinese megatron-bert 1257367552 21248 2048 24 8 [MASK]
model type param vocab embed layer heads maskMissing values of year tokens (1800~2019):
- All: 77 missing
- 1801~1839, 1841~1849, 1851~1859, 1861~1866, 1869, 1872~1879, 1881, 1883, 1887, 1891, 1892
Device Information
ℹ Device Info:
R Packages:
FMAT 2025.12
reticulate 1.44.1
Python Packages:
transformers 4.57.3
torch 2.9.1+cu130
huggingface-hub 0.36.0
NVIDIA GPU CUDA Support:
CUDA Enabled: TRUE
GPU (Device): NVIDIA GeForce RTX 5060 Laptop GPU(Tested 2025-12-14 on the developer’s computer: HP Zbook X ZHAN99 G1i 16 inch - Intel Ultra9 285H - 64GB/2T - NVIDIA GeForce RTX 5060 Laptop GPU - Mobile Workstation PC)
Related Packages
While the FMAT is an innovative method for the computational intelligent analysis of psychology and society, you may also seek for an integrative toolbox for other text-analytic methods. Another R package I developed—PsychWordVec—is useful and user-friendly for word embedding analysis (e.g., the Word Embedding Association Test, WEAT). Please refer to its documentation and feel free to use it.